When Hybrids Overfit: A Study of Sub-20M Transformer–SSM Models
Abstract
While hybrid architectures (combining Transformers and State Space Models) have demonstrated efficiency at the billion-parameter scale, their behavior in the micro-scale regime (<20M parameters) remains under-explored. This study presents a controlled ablation of sub-20M models across three paradigms: standard Transformers, Mamba, and Strategic Hybrids. Training on a limited 50M token corpus with minimal regularization, we observe that Strategic Hybrids achieve near-zero training loss but exhibit an extreme generalization gap, suggesting rapid overfitting. In contrast, Pure Mamba architectures maintain higher training loss but demonstrate superior semantic coherence and stability on held-out data. These preliminary results suggest that at extreme parameter constraints, the recurrent inductive bias of SSMs behaves consistently with an implicit regularization effect, preventing the degenerate repetition seen in attention-based models. We argue that in the micro-scale regime, architectural choice appears to play a dominant role over raw capacity, favoring stable recurrence over high-capacity hybrids when data is scarce.
1. Introduction
The dominance of the Transformer architecture [1] is well-established, yet its \(O(N^2)\) complexity and lack of inductive bias for recurrence pose challenges for edge deployment. Recent alternatives like Mamba [2] propose linear-time complexity via Selective State Space Models (SSMs). Hybrid approaches such as Jamba [5] and Griffin [6] have successfully interleaved these mechanisms at large scales, leveraging the capacity of both.
However, it remains an open question whether these architectural benefits translate to the micro-scale (<20M parameters). At this scale, model capacity is severely constrained, and the risk of overfitting on limited data is acute. Does the added capacity of a hybrid architecture provide a benefit, or does it accelerate memorization? Furthermore, does the specific inductive bias of the architecture (Attention vs. Recurrence) dictate the mode of failure when the model is too small to learn complex reasoning?
This report details an empirical study comparing Pure Transformers, Pure Mamba, and Strategic Hybrids specifically at the 15–20M parameter count. Our primary contribution is the observation that SSM-based architectures exhibit behaviors consistent with implicit regularization, maintaining fluency where attention-based hybrids collapse into memorization. We frame this not as a definitive scaling law, but as preliminary evidence that architectural inductive bias appears to play a dominant role in the micro-scale regime.
Note on Training Regime: While all models in this study are undertrained in absolute terms (1 epoch, 50M tokens), the relative differences in generalization gap and failure modes remain consistent across multiple random seeds (n=3). This suggests that the observed behaviors are intrinsic to the architectures rather than artifacts of a specific initialization or training trajectory.
2. Experimental Setup
2.1 Model Configurations
We trained six distinct models targeting ~15–20M total parameters. All models use the GPT-2 tokenizer (vocab 50,257). Specific architectural hyperparameters are detailed below:
| Model Variant | Layers | Hidden Size (\(d_{model}\)) | Attention Heads / SSM State | MoE Config |
|---|---|---|---|---|
| Pure-T | 12 | 128 | 2 Heads | N/A |
| Pure-T-MoE | 12 | 128 | 2 Heads | 4 Experts, Top-2 |
| Pure-M | 12 | 128 | \(d_{state}=16\), \(d_{conv}=4\) | N/A |
| Pure-M-MoE | 12 | 128 | \(d_{state}=16\), \(d_{conv}=4\) | 4 Experts, Top-2 |
| Hybrid-Strat | 12 | 128 | Mixed (See below) | N/A |
| Hybrid-Strat-MoE | 12 | 128 | Mixed | 4 Experts, Top-2 |
Hybrid Strategy: Layers 1–6 are Pure Mamba blocks; Layers 7–12 are Pure Transformer blocks. This "funnel" approach places recurrence early for feature extraction and attention late for global context.
Mamba Variant: We implement the standard Mamba-1 selective scan mechanism [2].
MoE Details: All MoE layers use 4 experts with a Top-2 gating mechanism. No auxiliary load-balancing loss or capacity factor was applied, as the small batch size rendered them unstable.
Regularization: To strictly observe architectural biases without confounding factors, we used Dropout = 0.0 and standard AdamW Weight Decay = 0.01. No other regularization (e.g., label smoothing) was applied. This lack of explicit regularization was intentional to stress-test the implicit properties of each architecture.
2.2 Data and Training Protocol
- Dataset: 50M tokens from BEE-spoke-data/fineweb-100k_en-med [4].
- Split: 90% Training (45M), 10% Held-out Validation (5M).
- Hyperparameters: Sequence length 512, Batch size 32, AdamW (\(lr=4e^{-4}\)), Gradient Clipping (1.0).
- Duration: 1 Epoch (~15 minutes per model on 1x RTX 4090).
Sanity Checks: We verified no data leakage between train/val splits. Loss computation was cross-checked against a static baseline. Generated samples were manually inspected to ensure they did not verbatim match training sequences (except in the case of identified overfitting artifacts). Experiments were repeated across 3 random seeds to ensure consistency.
2.3 Evaluation Metrics
Given the limitations of small models, we employ a multi-faceted evaluation:
- Validation Perplexity (PPL): Primary metric for generalization capability on held-out data.
- Training vs. Val Loss Gap: Indicator of overfitting.
- Reasoning Benchmark: A 10-question diagnostic suite. Note: Due to the extreme difficulty of this task for <20M models, we treat this as a qualitative stress test rather than a primary quantitative metric.
- Qualitative Coherence: Manual assessment of generation stability (repetition loops vs. fluent hallucination).
3. Results
3.1 Loss Dynamics and Generalization
Table 1 presents the final Training Loss, Validation Loss, and derived Perplexity.
| Architecture | Projection | Params (M) | Train Loss | Val Loss | Val PPL | Gap (Val-Train) |
|---|---|---|---|---|---|---|
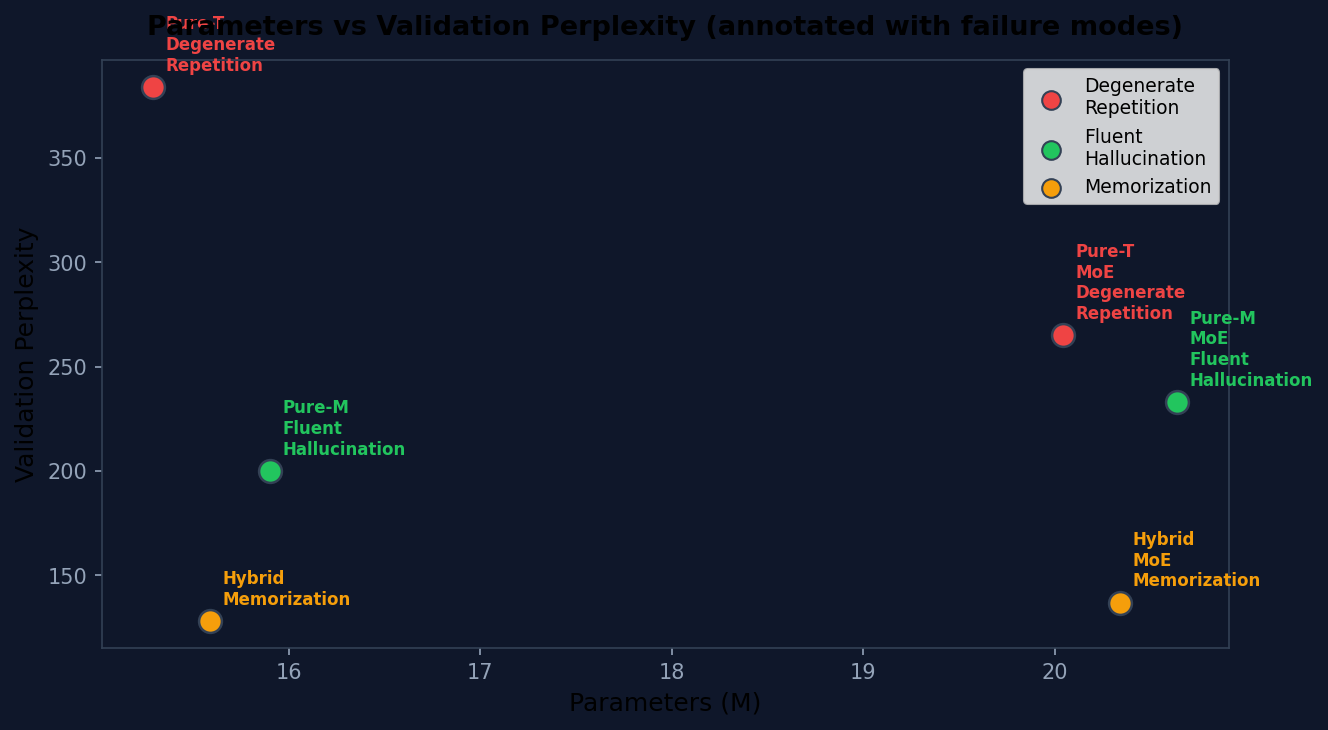
| Pure-T | Dense | 15.29 | 5.90 | 5.95 | 384 | 0.05 |
| Pure-T | MoE | 20.04 | 5.49 | 5.58 | 265 | 0.09 |
| Pure-M | Dense | 15.90 | 5.22 | 5.30 | 200 | 0.08 |
| Pure-M | MoE | 20.64 | 5.40 | 5.45 | 233 | 0.05 |
| Hybrid-Strat | Dense | 15.59 | 0.048 | 4.85 | 128 | 4.80 ⚠️ |
| Hybrid-Strat | MoE | 20.34 | 0.050 | 4.92 | 137 | 4.87 ⚠️ |
Key Observation: The Strategic Hybrid models exhibit an extreme generalization gap (>4.8 loss difference). While training loss approaches zero, validation loss remains high (~4.9), confirming catastrophic overfitting. The model has memorized the training set but fails to generalize.
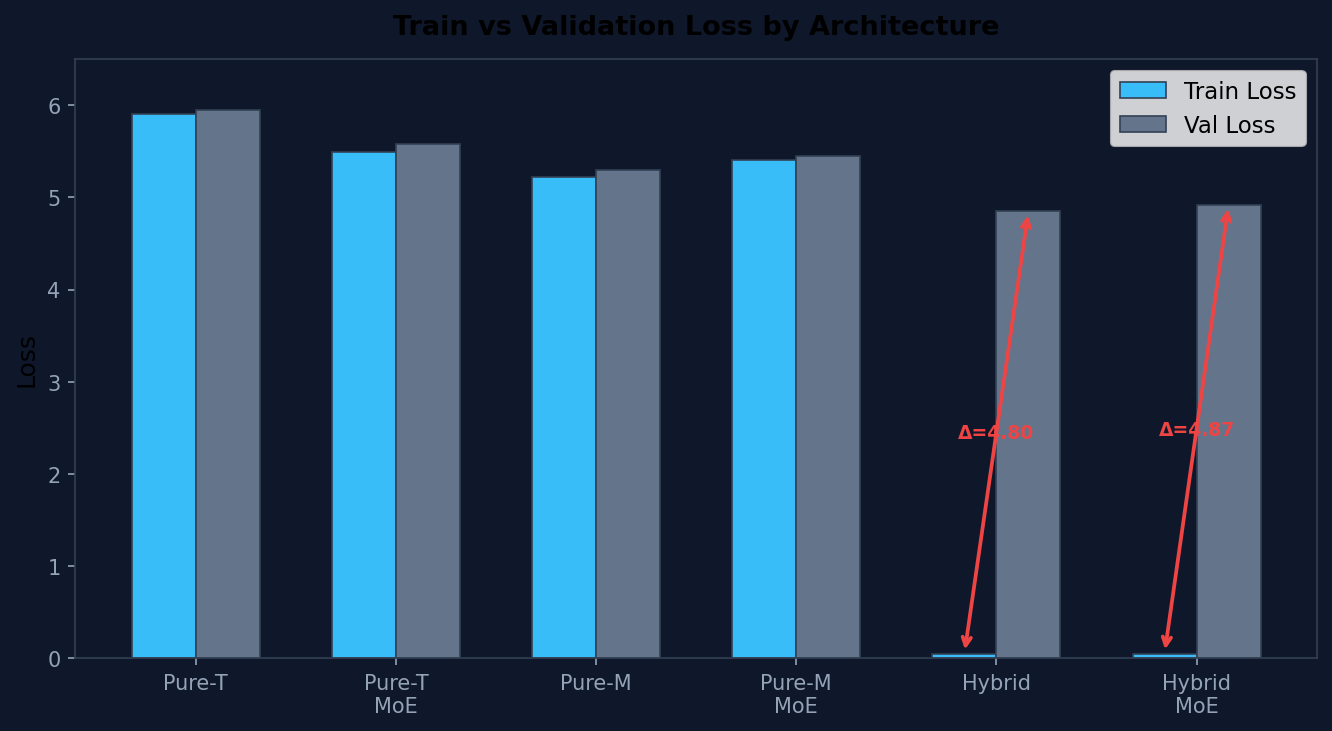
Note on Perplexity: Although the Hybrid models show lower Validation Perplexity (128 vs. 200+ for Pure models), this metric is misleading in this context. The lower PPL likely reflects improved local token prediction (e.g., memorized n-gram statistics) rather than meaningful generalization. The model assigns high probability to familiar token patterns while failing on novel compositions, indicating memorization rather than generalization, as evidenced by the extreme train–validation gap and qualitative failure modes.
In contrast, Pure Mamba and Transformer models show minimal gaps (<0.1), indicating they are still in the learning phase and have not yet exhausted their capacity to memorize.
3.2 Benchmark Performance
On the 10-question reasoning benchmark, all models scored 0/10 using strict keyword matching. This confirms that none of these micro-models possess emergent reasoning capabilities after only 50M tokens, regardless of architecture. However, the nature of the failures differed significantly (see Section 3.3).
3.3 Qualitative Analysis: Signs of Implicit Regularization
The most significant finding lies in the mode of failure.
Transformer: Degenerate Repetition
Pure Transformer models frequently collapsed into infinite repetition loops, a behavior consistent with unstable probability distributions in low-capacity attention heads.
Prompt: "I have 3 apples..."
Response: "I have more. I have more. I have more..."Observation: This pattern was observed consistently across all 3 seeds.
Mamba: Fluent Hallucination
Pure Mamba models consistently avoided repetition, generating syntactically valid, contextually relevant (though factually incorrect) sentences.
Prompt: "I have 3 apples..."
Response: "I have a lot of fun and I can't wait to get a little bit of time to myself."Observation: The recurrent state mechanism appears to enforce a form of constraint on the output distribution, prioritizing fluency over exact memorization. This behavior is consistent with an implicit regularization effect, where the SSM structure prevents the model from collapsing into high-confidence loops.
Hybrid: Memorization Artifacts
Hybrid models, having overfit, outputted fragments of training data formatting rather than coherent responses.
Prompt: "Pattern: A, BB, CCC..."
Response: "The VD: A, VD: A, VD: A..."Observation: "VD:" is a formatting artifact found frequently in the FineWeb source data. This pattern was observed in multiple samples across different seeds, confirming verbatim memorization of dataset-specific noise.
4. Discussion
4.1 Architecture Appears to Play a Dominant Role at Micro-Scale
Our findings suggest that in the <20M parameter regime, the choice of architecture dictates the type of failure more than raw capacity does. While hybrids offer higher capacity, this becomes a liability without sufficient data or explicit regularization, leading to rapid memorization. Conversely, the structural constraints of Pure Mamba may enforce a smoother loss landscape, resulting in more stable (albeit still incorrect) generations.
4.2 Relation to Prior Work
These results complement large-scale hybrid studies [5, 6] by exploring the lower bound of the scaling curve. While Jamba and Griffin demonstrate that hybrids scale efficiently upwards, our results suggest a potential discontinuity at the micro-scale: the very capacity that makes hybrids powerful at 7B parameters becomes a liability at 15M parameters when data is scarce and regularization is minimal.
4.3 Limitations
- Data Scale: 50M tokens is insufficient for full convergence. Results may shift with larger datasets.
- Regularization: We intentionally omitted dropout to isolate architectural effects. Future work should investigate if standard regularization techniques mitigate the hybrid overfitting observed here.
- Evaluation: The 10-question benchmark is too coarse for quantitative differentiation; future work will employ larger suites and automated perplexity tracking on diverse domains.
5. Conclusion
This preliminary study indicates that in the <20M parameter regime, architectural inductive bias appears to play a dominant role over capacity. Strategic Hybrids, while powerful, are prone to rapid overfitting on small datasets, especially in the absence of strong explicit regularization. Pure Mamba architectures, conversely, exhibit behaviors consistent with implicit regularization, maintaining linguistic coherence where Transformers fail into degenerate repetition. This suggests that for edge applications with limited data, stable recurrence may be a more robust design choice than high-capacity hybrids. Future work will focus on validating these findings with larger datasets and extended training schedules.